上一篇写了 Claude Code 的深度使用指南,提到了 Skills 机制——可以给 Claude Code 加载按需触发的专家模式。
这篇介绍一个我最近在用的 Skill 集合:Superpowers。
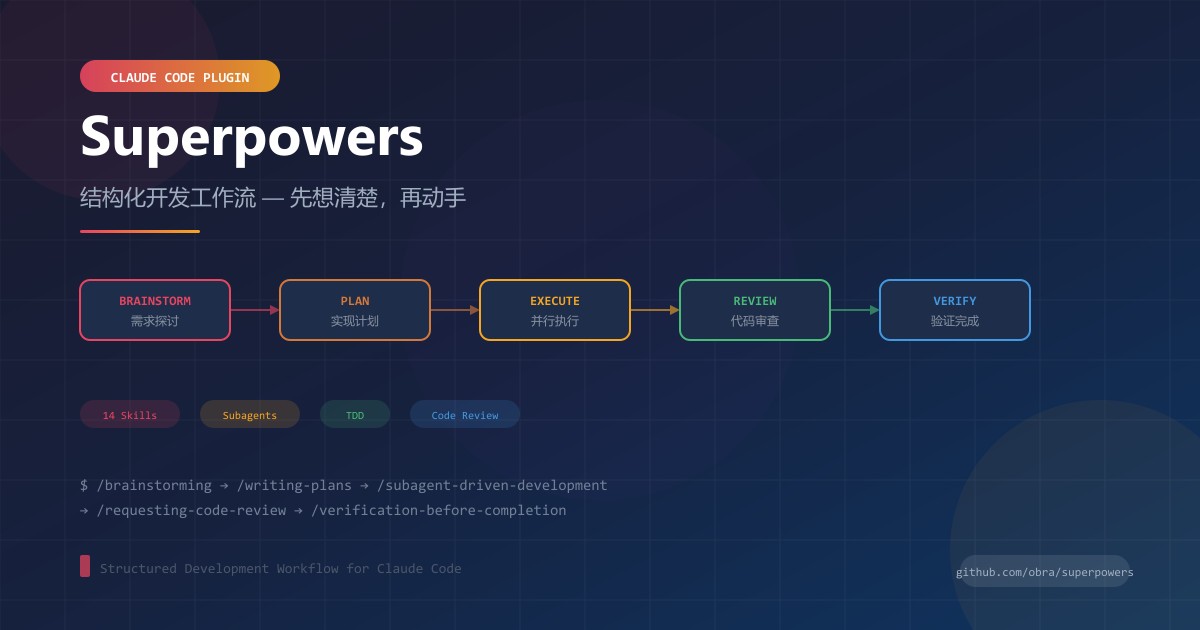
一句话总结:它让 Claude Code 从"接到需求就开始写代码"变成"先想清楚再动手"。
为什么需要它
用 Claude Code 做过稍微复杂一点的功能都会有这种体验:
你说"给画布加个批量导出",它马上就开始改文件。改了十几个文件之后,你发现它理解的"批量导出"和你想的完全不是一回事。或者更常见的情况——改到一半发现前面的架构决策有问题,但回头重来的成本已经很高了。
问题不在模型能力,而在于没有流程约束。
人类团队做开发有需求评审、技术方案、代码审查、测试验收。但 Claude Code 默认什么都没有——它是一个能力很强但没有流程纪律的开发者。
Superpowers 就是给它加上这套纪律。
安装
在 Claude Code 里执行三条命令:
| |
完事。没有额外依赖,不需要配置文件。
14 个 Skill 总览
Superpowers 包含 14 个 Skill,按开发流程排列:
| 阶段 | Skill | 一句话说明 |
|---|---|---|
| 需求 | /brainstorming | 探讨需求,输出设计文档 |
| 计划 | /writing-plans | 拆解为 2-5 分钟粒度的执行步骤 |
| 执行 | /executing-plans | 串行逐步执行计划 |
| 执行 | /subagent-driven-development | 并行子代理执行(推荐) |
| 执行 | /dispatching-parallel-agents | 派发多个不相关任务 |
| 执行 | /test-driven-development | Red-Green-Refactor 循环 |
| 调试 | /systematic-debugging | 系统化根因分析 |
| 审查 | /requesting-code-review | 派 subagent 审查代码 |
| 审查 | /receiving-code-review | 理性处理 review 反馈 |
| 验证 | /verification-before-completion | 跑测试才能说"完成了" |
| 收尾 | /finishing-a-development-branch | 合并/PR/清理 |
| 工具 | /using-git-worktrees | 隔离环境开发 |
| 工具 | /writing-skills | 编写自定义 Skill |
| 工具 | /using-superpowers | 会话初始化(自动触发) |
不需要全部用。简单改动直接写代码就行,复杂功能再走流程。
核心 Skill 详解
/brainstorming — 先想清楚再写
这是整个插件最有价值的部分。
触发后 Claude 不会动任何文件,而是:
- 读取项目上下文(代码结构、已有实现)
- 向你提问,澄清模糊的需求
- 给出 2-3 种方案,对比优劣
- 确认后输出设计文档
你:我想给画布添加批量导出 PNG 功能
Claude:(不写代码,先问)
→ 导出范围:整个画布 vs 选中节点?
→ 分辨率:屏幕分辨率 vs 自定义 DPI?
→ 触发方式:右键菜单 vs 工具栏按钮?
→ 方案 A: html-to-image 前端截图
优点:不依赖后端,实现简单
缺点:跨域图片可能白屏
→ 方案 B: Puppeteer 后端渲染
优点:稳定,支持高分辨率
缺点:需要部署无头浏览器
→ 方案 C: Canvas API 原生绘制
优点:性能最好,可控性强
缺点:实现复杂,要手动处理每种节点
设计文档会保存到 docs/superpowers/specs/ 目录,后续可以回溯。
为什么重要:我之前让 Claude Code 做一个"分镜面板拖拽排序"功能,它直接用了 react-beautiful-dnd。做完才发现这个库和 ReactFlow 有冲突。如果先 brainstorming,这个问题在方案评估阶段就能被发现。
/writing-plans — 把设计拆成可执行的步骤
接收设计文档(或者你口头描述的需求),输出一份极细粒度的实现计划。
它的设计哲学是:假设执行者对这个项目一无所知。所以每个步骤都会写清楚:改哪个文件、改什么内容、改完怎么验证。
| |
注意粒度——“写测试"和"运行测试"是两个独立步骤。这不是教条,而是因为每个步骤可能被分配给不同的 subagent 执行,粒度越细越不容易出错。
计划写好后会自动派 subagent 审查,最多 3 轮修订,确保计划本身没有漏洞。
保存到 docs/superpowers/plans/ 目录。
/subagent-driven-development — 并行执行,双重审查
这是执行阶段的推荐选项。
对于计划中每个独立的 Task,它会启动一个 subagent 去执行。多个互不依赖的 Task 可以同时跑。
关键在于每个 Task 完成后的双重审查:
Subagent 完成 Task
↓
Spec Review — 对照设计文档检查功能是否正确
↓
Code Quality Review — 检查代码质量、边界情况
↓
通过 → 标记完成
不通过 → 打回修改
它还会根据任务复杂度自动选择模型——机械性任务用 Haiku(便宜快),架构性任务用 Opus(贵但准)。
/systematic-debugging — 不许瞎猜
遇到 bug 时用。核心铁律:没找到根因,就不尝试修复。
它把调试分成四个严格的阶段,不允许跳步:
阶段 1: 根因调查
→ 读完整错误信息(不是扫一眼)
→ 复现问题
→ 检查最近变更(git log)
→ 收集证据
阶段 2: 模式分析
→ 找到能正常工作的类似代码
→ 对比差异
→ 缩小范围
阶段 3: 假设验证
→ 形成理论
→ 最小化测试验证
阶段 4: 实施修复
→ 先写测试
→ 再修代码
→ 运行验证
红旗机制:如果修了 3 次还没好,它会停下来说"这可能是架构问题”,建议你重新思考方向而不是继续头痛医头。
这解决了 Claude Code 一个常见问题——遇到 bug 就开始改代码试,试了五六种方案都不行,每次都是微调上一次的方案。systematic-debugging 强制它先理解问题再动手。
/test-driven-development — 测试先行
强制 Red-Green-Refactor 循环:
RED → 写一个会失败的测试 → 运行 → 确认失败 → 确认是因为正确的原因失败
GREEN → 写刚好让测试通过的代码(不多写一行)
REFACTOR → 保持测试绿色的前提下重构
铁律:没看到测试失败,就不写实现代码。
为什么要看到失败?因为如果测试一开始就是绿的,你不知道它是不是在测正确的东西。一个永远通过的测试等于没有测试。
/verification-before-completion — 不许说"应该没问题"
这个 Skill 在你准备说"搞定了"之前触发。
铁律:没有运行验证命令并确认输出,就不能声称完成。
❌ "测试应该能过"
❌ "改动很小,应该没影响"
❌ "和之前类似的改法,大概没问题"
✅ npm run test → 输出 "42 passed, 0 failed" → 截图证据 → "完成"
/finishing-a-development-branch — 收尾
功能做完、测试通过后,引导你完成最后一步:
| 选项 | 操作 |
|---|---|
| 本地合并 | merge 到目标分支 |
| 推送并创建 PR | push + gh pr create |
| 保持现状 | 不动,稍后处理 |
| 丢弃 | 删除分支和变更 |
前提条件:测试必须通过,否则不让你继续。
实际使用模式
不需要每次都走完整流程,按需组合:
模式 A:完整功能开发
/brainstorming
↓
/writing-plans
↓
/subagent-driven-development
↓
/verification-before-completion
↓
/finishing-a-development-branch
适合:新功能、大重构、跨多个文件的改动。
模式 B:快速修 Bug
/systematic-debugging → 修复 → /verification-before-completion
适合:线上 bug、测试挂了。
模式 C:测试先行
/writing-plans → /test-driven-development → /verification-before-completion
适合:对正确性要求高的核心模块。
模式 D:只要计划
/brainstorming → /writing-plans
拿到计划后自己执行,或者交给团队其他人。
文件输出
Superpowers 会生成两类文件:
| 类型 | 路径 | 内容 |
|---|---|---|
| 设计文档 | docs/superpowers/specs/YYYY-MM-DD-<topic>-design.md | brainstorming 的产出 |
| 实现计划 | docs/superpowers/plans/YYYY-MM-DD-<feature-name>.md | writing-plans 的产出 |
这些文件可以提交到仓库,作为技术决策的历史记录。回头翻看"当时为什么选了方案 A 而不是方案 B"很有用。
和上一篇的关系
在 Claude Code 深度使用指南 里我提到了三层治理:
CLAUDE.md → 声明规则
Skill → 定义流程
Hook → 硬性校验
Superpowers 是流程层的一套现成方案。你不需要自己从零写 Skill 来约束 Claude Code 的开发流程——安装 Superpowers 就有了一套经过打磨的工作流。
当然,它不能替代 CLAUDE.md 和 Hooks。三层各管各的:
- CLAUDE.md:告诉 Claude “这个项目的规矩是什么”
- Superpowers:告诉 Claude “做事的流程是什么”
- Hooks:保证"违规了会被拦住"
适合谁
适合:
- 用 Claude Code 做跨多文件的功能开发
- 经常遇到"改完才发现方向不对"的返工
- 希望 AI 有测试纪律和审查流程
- 需要把 AI 的工作产出交给团队 review
不太需要:
- 只做单文件的小改动
- 改个 CSS、修个 typo 之类的简单任务
- 你自己就是需求方,不需要需求澄清
它不会让 AI 变得更聪明,但会让它变得更有纪律。就像一个能力很强但没有流程意识的初级开发者——给他加上代码审查和测试要求之后,产出质量会上一个台阶。
链接
- 仓库:https://github.com/obra/superpowers
- 安装命令:
/plugin install superpowers@superpowers-marketplace - 前置条件:Claude Code
说些什么吧!